 |
Salt
3.3.6-SNAPSHOT
A powerful, tagset-independent and theory-neutral meta model and API for storing, manipulating, and representing nearly all types of linguistic data .
|
|
Salt
3.3.6-SNAPSHOT
A powerful, tagset-independent and theory-neutral meta model and API for storing, manipulating, and representing nearly all types of linguistic data .
|
In this article, we present a very simple example to show how to create a Salt model in a very brief way. The example is given to clarify the mechanisms of Salt and therefore does not claim to advocate a specific linguistic school.
Due to its graph-based structure, even sub- and super-corpora are modeled as nodes having relations connecting them and creating a containment relationship. The only element not following the graph approach is the element SaltProject. This element serves as container for a set of corpus structures represented via the model element SCorpusGraph. Such a corpus structure is organized as a graph and contains corpora and documents. Salt distinguishes between a corpus (which can contain other corpora and documents) and documents (which only contain the document structure). The document structure itself is organized as a graph called SDocumentGraph. The SDocumentGraph is the element containing the primary data and the linguistic analysis. The corpus structure is just for organizing a complex linguistic project. A corpus in Salt is represented by the element SCorpus and a document is represented by the element SDocument. In this section, we create a simple corpus structure having one corpus and one document. Since corpora and documents are nodes, they can be labeled. To show this mechanism, we create a meta annotation, defining the annotator of that corpus. A meta annotation is represented via the element SMetaAnnotation. The corpus structure created here is shown in the figure below.

The following snippet shows the creation of the container object SaltProject, which shall contain our corpus model.
The next snippet illustrates the creation of the corpus structure by creating a corpus graph, a corpus named 'sampleCorpus' and a document named 'sampleDocument'. Afterwards, the creation of the corpus is shown, followed by a meta annotation declaring its annotator.
The meta annotation is created via the method createSMetaAnnotation(). This method takes three arguments: a namespace which is optional and can be used to take up further information, the name of the annotation and the value of the annotation.
We now create the document that will later contain a primary text and all of its annotations. We present two ways of creating a document. First an easier way, where we use helpful methods provided by Salt and second an alternative, where we do it manually.
Alternatively you can add an already existing document to the corpus structure and use the addDocument method.
Now we are leaving the corpus structure and go to the document structure. The difference between both is that the corpus structure groups corpora and documents to super- and sub-corpora and documents, and the document structure contains primary data and their annotations. Therefore we need to add an SDocumentGraph object to the SDocument, which acts as container for the primary data and linguistic annotations.
We now show how to add a primary text like "Is this example more complicated than it appears to?" to the document graph. We first show the easy way of creating primary data and than we show the more explicit way.
Even the primary text and in general the primary data in Salt are modeled as nodes with labels. The specific node, which is the container for the primary text is the node STextualDS, which is a subclass of SSequentialDS. The String representing the text is stored in a label of that node, which can be accessed via STextualDS.getSText() or STextualDS.setSText(text).
Sometimes it might be necessary to manually tokenize a text yourself. For instance if you don't want to have a word tokenization, or for historical text, where separators are missing.
A token in Salt is not bound to a linguistic unit - in this example we show how to tokenize words, although tokenizations by characters, syllables or sentences and so on are possible, too. The following figure shows an excerpt of the document graph we want to model in Salt. The figure only shows the tokens overlapping the words 'Is', 'this', 'example' and '.'.
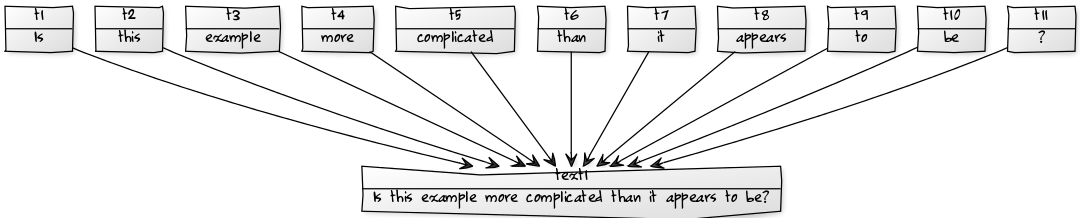
For tokenizing a primary text, we need the character offset of the start and the end position for each token in the text. The word "Is" in the sample text, for instance, has the start position 0 and the end position 2. Note that the positions are counted between two characters.
| Is | BLANK | this | BLANK | example | BLANK | more | BLANK | complicated | BLANK | than | BLANK | it | BLANK | appears | BLANK | to | BLANK | be | ? | |||||||||||||||||||||
| 0 | 2 | 3 | 7 | 8 | 15 | 16 | 20 | 21 | 32 | 33 | 37 | 38 | 40 | 41 | 48 | 49 | 51 | 52 | 54 | 55 |
In the given table, BLANK is an alias for the whitespace character (' ').
Salt provides a tokenizer to tokenize a primary text. This tokenizer is an adaptation of the TreeTagger tokenizer (see: http://www.cis.uni-muenchen.de/~schmid/tools/TreeTagger/). The tokenizer uses blanks and punctuation (taking abbreviations into account), and so on, to separate words. The usage of the tokenizer is quite simple as the following snippet shows:
To access the created tokens you can iterate over the token's list:
or token by token:
In the following snippet we show an example of creating a tokenization manually by creating just one token. The creation of all other tokens is done in the same manner.
Now the token will be added to the morphology layer. A layer in Salt is represented by the element SLayer and defines a kind of a sub-graph, for instance for clustering nodes in a specific linguistic analysis. The snippet also shows the annotation of tokens with part-of-speech and lemma annotations using the element SAnnotation.
Again, we did not explicitly create the relations: their creation is hidden in the method createSToken(). But in the background Salt creates a node of type SToken for the token and a relation called STextualRelation which connects the token and the primary data node. Since Salt does not know any further elements other than the graph elements mentioned, the character positions, to which the tokens refer, are stored as labels of the relations. For such a kind of label we use a special type named SFeature. When just working with Salt and not creating an own derived meta model, the mechanism is not important. It is just important, that the positions can be set and retrieved via the methods STextualRelation.getSStart() or STextualRelation.setSStart(value). The same goes for the end position SEnd.
In Salt you can create hierarchies, e.g., in order to model syntactic annotations such as constituents. These hierarchies are realized via the node SStructure and can be connected to each other via relations of type SDominanceRelation. A relation of that type has the semantics of a part-of relation, which means that the target of that relation is a part of the source of that relation. In this example, we want to create a syntactic analysis as part of a syntactic layer. The following figure shows the structure we will create in this step of the example.
The following snippet gives an impression of how to create that hierarchy. We just show the creation of the left NP node and the SQ node.
For annotating a dominance relation or any other relation, you can access it by querying all relations between two nodes:
sampleDocument.getDocumentGraph().getRelations(np_1.getId(), tok_is.getId()).get(0).createAnnotation("myNamespace", "myName", "myValue");
Alternatively, you can create a hierarchy one step after another. The following snippet exemplifies this process for the same sample (the token for 'is' and the SQ node):
If a whole (possibly discontinuous) set of nodes has to be annotated with the very same annotation, a span can be used to aggregate the nodes. Instead of an annotation for each node, a single annotation for the span can be created then. This annotation belongs to the set of nodes (the span), but not to any of the single nodes. In our example we show the use of spans building an information structure analysis. Spans in Salt are realized by nodes of the type SSpan, they are connected to SToken nodes via relations of type SSpanningRelation. The following figure shows the information structure analysis to be modeled.
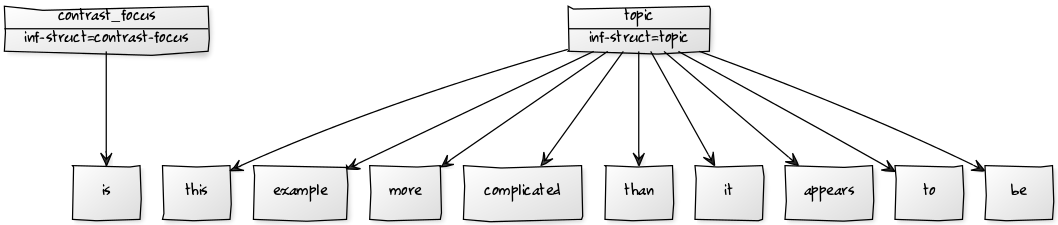
The following snippet shows the code used to create the analysis shown in the figure.
Alternatively to using the method createSSpan(...) you can create the span and the corresponding SSpanningRelations on your own. The following snippet gives an impression of how to create the same span as in the last example, step by step:
Now we will show another type of relation, which renders a more loose relation between nodes. In contrast to SSpanningRelations and SDominanceRelations, which can only connect specific kinds of nodes, the type SPointingRelation can connect SToken, SSpan and SStructure nodes with each other and vice versa. These relations for instance can be used to model anaphoric relations between words, phrases, sentences and so on. Relations in general can be typed with a linguistic meaning by setting their attribute SType. We illustrate that by connecting the token covering the word "it" to the set of tokens "the" and "example". To bundle the words "the" and "example", we first have to create a span covering both tokens "the" and "example" following the same mechanism as shown in section Spans.
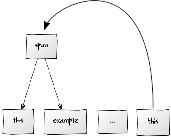
The following snippet shows the creation of the model shown in the figure.
You can download the demonstrated code via github under https://github.com/korpling/saltDemo. More code samples can be found in Salt's sample package.
To learn how to access the elements of a Salt model, please read the article Access a Salt model.
 1.8.11
1.8.11 
